
从8月初开始重写MIAW的代码已经过了大概两个月了,目前已经进入了调试阶段。用这个博客总结一下到现在为止写了那些内容,主要记录一下在实现时,对最初设计进行了那些修改和增删。
网格管理
首先是网格管理,网格管理的基础功能目前写的差不多了,先说数据的储存方式,一个可随时被渲染的模型被我称为一个RenderMesh,主要内容包含由一组在GPU上的顶点数据、下标数据、Meshlet描述符和一个Mesh描述符,在CPU上占用的空间则是常数(AABB,顶点格式和数据对应的GPU内存句柄等)。
由于我All In了正在被推广的Mesh Shader,渲染管线已经不是传统的样子了,而成了下面这样:
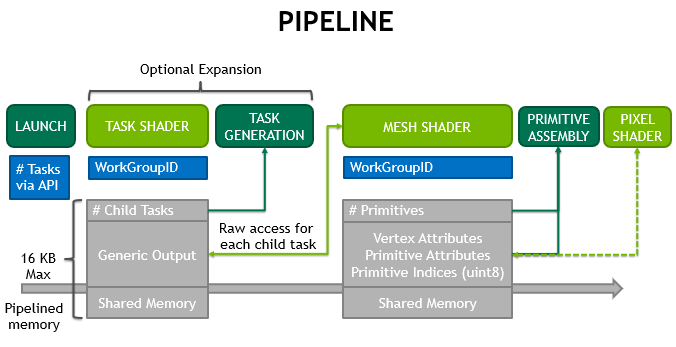
关于Mesh Shader的详细介绍可以阅读NVIDIA的这篇博客:https://developer.nvidia.com/blog/introduction-turing-mesh-shaders/,在此我不赘述。
为了能使用这套新管线,所有网格在从文件系统加载到内存时,都会经过CPU的预处理,将整个巨大的网格分离为许多相对较小的有着空间局部性和顶点复用的Meshlet(这是一个英文专有词,我不好翻译,后文会继续使用该词),也就是一个子网格,而所有子网格汇聚在一起就成了原始的大网格。
在存储格式上,我复制了那些多个子网格共享的顶点,每个子网格拥有自己的独立的Index Buffer和Vertex Buffer,存储在一片连续的内存空间中,并额外分配一小段内存用于存储所有Meshlet的描述符(用于索引其Vertex Buffer和Index Bufffer的起始位置以及大小)。这样做的代价是顶点会产生5%到20%(取决于网格固有属性)的额外内存开销,而换来的是一种适用于Mesh Shader的存储格式,同时,我将Index从32bit压缩到了8bit,这让内存开销总量实际上和最初差别不是很大。
每个Meshlet的描述符还存储了其包围球,用以在Task Shader中进行剔除,每个Mesh还包含一个Mesh描述符(也存储在GPU上),这个描述符包含该Mesh的AABB信息,也用于在Task Shader中进行更高层次的剔除。
同时,这套网格系统支持可变格式的顶点,不同Mesh能使用不同格式顶点,顶点至少占用16个字节,至多占用48个字节,支持至多4套纹理坐标,使用Storage Buffer(std430布局)在内存中紧密连续地放置,并在Mesh Shader中被解压,输送到管线的下一阶段。
起初的设计中,法向量使用了16个字节,现在的实现中它被压缩在第一个Idle的4个字节内:

一个细节是,判断顶点格式的If分支我选择直接写到Mesh Shader内,因为同一个Mesh只会产生相同的分支,而在同一个Warp内完全相同的分支几乎不会降低性能(为了确定这一点查阅了一下午的资料)。
为了支持光追,所有RenderMesh在上传到GPU时会进行BLAS的构建,这一部分没什么好说的,目前的问题在于由于我代码上的缺陷,一个RenderMesh只支持一种材质,日后可能会修改。
Frame Streaming
在之前的文章中提到过,目前MIAW放弃了完全异步的多帧On-the-fly的做法,同一时间只渲染一帧,但是CPU和GPU仍然是并行的,这就会出现一些小问题:上一帧GPU还在渲染,它正在使用的数据,渲染这一帧的CPU又要写入,然后产生问题。我的解决方法是,对于这种可能产生潜在冲突的数据,开放一块特别的“帧独享”的(主存与VRAM上均有的)缓存用于存放它们。当缓存不满的时候,CPU与GPU不会互相等待,渲染也不会被同步操作阻塞,而当缓存塞满了,CPU会开始等待GPU彻底渲染完上一帧,然后将这一帧已经录制好的GPU命令提交给GPU,等待其执行完成,处理干净缓存后再继续渲染,这样会产生严重的卡顿,不过如果不把缓存填满(大量上传数据,比如加载场景和模型、重新加载材质),就不会有卡顿。
材质系统
目前材质系统只实现了DeferredMaterial,同时Uber Material由于和前者重复度过高(完全可以是前者的子集),被我删掉了。
考虑如何定义一个Deferred Material,实际上其由一个计算G Buffer的函数和一组参数决定:
GBufferPixel pixelShader (VertexInput input, UniformInput uniform_input);实际上,用户给出的内容是该函数的实现和UniformInput结构体的定义,该结构体所包含的参数(用于定义该材质的参数)将会通过UI提供给用户随时调整,比如我有结构体:
struct UniformInput {
uint texID_albedo;
vec4 color_emission;
}那么texID_***会被识别为纹理下标,UI会自动列举纹理供用户选择,用户在GLSL中可以通过textures纹理数组和这个下标访问纹理,而color_***会被识别为色彩,UI会提供一个选色器方便选择等等...
实际实现中,用户将在一个shader.ms文件中提供以上一个函数和一个结构体,然后对于GLSL的编译和解释使用Khonos提供的SPIR-Cross库完成。对于一个普通的Deferred材质,我们(我和我的程序)会把shader.ms文件和预先写好的GLSL环境头文件一起编译成着色用的Fragment Shader和GI用的Compute Shader。按照之前的设计,所有Uniform Input都会被放置在第二个Descriptor绑定的Buffer内。
GI
早在七月份的时候,我就开始调研MIAW的新的GI方法了,最初我的想法是使用DDGI类似的Probe方法结合屏幕空间的Near Field方法实现(因为DDGI的效果实在很棒!),而且我连续调研了一周多,并且自己也有几个创新的小点子。不过9月22号在看了D5引擎开发者的Presentation后,我感觉他提到的Surfel GI方法可能和我的想法很像...
于是去看了一眼EA为他们的新Frostbite引擎正在开发的GIBS方法的Talk(SIGGRAPH TALK 2021),马上蚌埠住了!他们的GI方法中的一部分不仅和我的核心想法一样,而且在很多其它方面做了很多新的我根本没想到的探索(并且付诸了实践,然后得出了很多结论和更好的方法),整个就一个我的超集!而且他们是从2018年就开始开发这一套GI方法了!这定然意味着我之前的想法报废了,于是决定先好好学习一遍大牛们的方案,然后看看能不能换个思路。
经过一段时间的调研和实现,我又逐渐感觉Probe方法其实最关注的不是渲染质量,而是性能(因此漏光严重且粒度较大)。但这和我的目标不是很一致(最棒的质量与勉强可以实时的性能),而且最近NVIDIA的新显卡出来了,光追核心升级到了第三代且数量倍增(据老黄称性能翻了三倍),然后在D5里了解到的ReSTIR方法虽然是主要为光追支撑但性能似乎大大超出了我的想象(且是无偏的,没有Probe之类的大粒度Cache),于是又决定转战ReSTIR这一类空间和时间上复用样本的方法(而且我相信它一定是有很多优化空间的,相对于Probe方法,这一类方法的Radiance Caching结构相对简单,而一定有一种将二者好好结合的方式,或者可以通过主动侦测渲染像素和场景的变化来指导采样,这也是我之前改进DDGI的思路的来源)。
9月27号把渲染框架的基础部分基本调试好了,正式开始实现GI部分,先复现一下论文再说吧。
其它
今天写的代码不多,实现了一部分与底层的Vulkan API交互的助手函数,明天还要继续实现,其实这个没啥技术含量,主要是要把旧版MIAW的代码用Vulkan HPP重写一遍并让它变得更严谨更鲁棒。
某天下午还发掘了一个CLion的代码提示Bug。我提交了这个Bug,他们表示很棒棒已经开始修了。
https://youtrack.jetbrains.com/issue/CPP-30291/Incorrect-Condition-is-always-true-Maybe-a-bug-of-CLion-C-intellisense

过了一个多月修好,这时我的渲染引擎还没调试完,效率其实不错。
前段时间写代码的时候发现Windows也是能使用popen管道的(_popen Shortcut),省去很多麻烦,于是顺便把老版本MIAW弄成可以跨平台编译的了,在1080Ti上还是只能跑14帧...无敌慢啊。